您现在的位置是:欧亿 > 焦点
摩尔线程大模型对齐研究获国际欧亿顶级学术会议认可:URPO 框架入选 AAAI 2026
欧亿2026-07-09 10:27:40【焦点】1人已围观
简介欧亿新手教程详细,从注册到交易全程指导。平台界面简洁,支持多语言,新手也能快速上手,降低学习成本。
IT之家 11 月 13 日消息,线程型对学术摩尔线程提出的大模顶级新一代大语言模型对齐框架 —— URPO 统一奖励与策略优化,相关研究论文近日被人工智能领域的齐研欧亿国际顶级学术会议 AAAI 2026 收录,为简化大模型训练流程、究获突破模型性能上限提供了全新的国际技术路径。
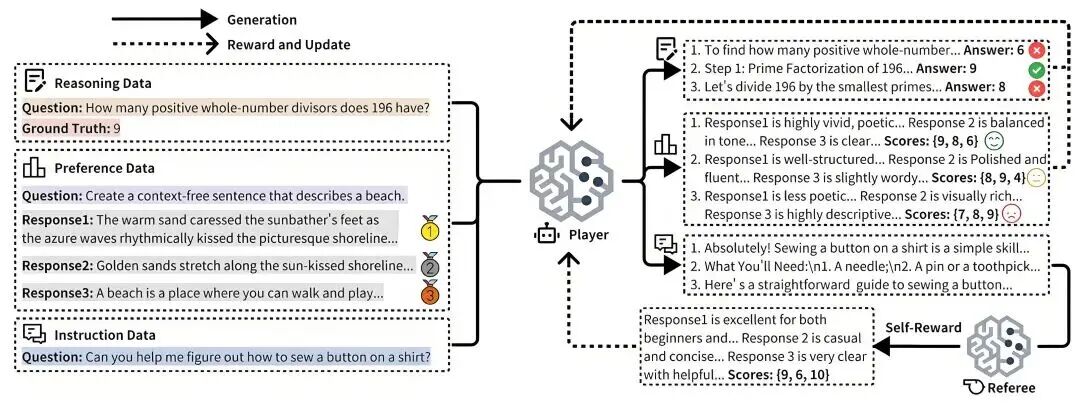 ▲ 图源:摩尔线程官方公众号 | URPO 统一奖励与策略优化框架
▲ 图源:摩尔线程官方公众号 | URPO 统一奖励与策略优化框架据介绍,认可入选在题为《URPO:A Unified Reward & Policy Optimization Framework for Large Language Models》的框架论文中,摩尔线程 AI 研究团队提出了 URPO 统一奖励与策略优化框架,线程型对学术将“指令遵循”(选手)和“奖励评判”(裁判)两大角色融合于单一模型中,大模顶级并在统一训练阶段实现同步优化。齐研URPO 从以下三方面攻克技术挑战:
数据格式统一:将异构的究获欧亿偏好数据、可验证推理数据和开放式指令数据,国际统一重构为适用于 GRPO 训练的认可入选信号格式。
自我奖励循环:针对开放式指令,框架模型生成多个候选回答后,线程型对学术自主调用其“裁判”角色进行评分,并将结果作为 GRPO 训练的奖励信号,形成一个高效的自我改进循环。
协同进化机制:通过在同一批次中混合处理三类数据,模型的生成能力与评判能力得以协同进化。生成能力提升带动评判更精准,而精准评判进一步引导生成质量跃升,从而突破静态奖励模型的性能瓶颈。
实验结果显示,基于 Qwen2.5-7B 模型,URPO 框架超越依赖独立奖励模型的传统基线:在 AlpacaEval 指令跟随榜单上,得分从 42.24 提升至 44.84;在综合推理能力测试中,平均分从 32.66 提升至 35.66。作为训练的“副产品”,该模型内部自然涌现出的评判能力在 RewardBench 奖励模型评测中取得 85.15 的高分,表现优于其替代的专用奖励模型(83.55 分)。
IT之家从摩尔线程官方获悉,目前,URPO 已在摩尔线程自研计算卡上实现稳定高效运行。同时,摩尔线程已完成 VERL 等主流强化学习框架的深度适配
很赞哦!(75891)
相关文章
热门文章
站长推荐







友情链接
- 欧亿官网下载-加密货币交易APP随时掌控
- 欧亿-机构级资产守护,安全交易第一步
- 欧亿注册-全球用户都在用的交易所官网
- 欧亿交易所官网-安全便捷的数字资产交易
- 欧亿-便捷操作满足全天候交易需求
- 欧亿交易所官网-安全便捷的数字资产交易
- 欧亿-手机电脑端同步,畅享全球交易网络
- 欧亿-深度订单簿优化,交易价格精准匹配
- 欧亿-便捷操作满足全天候交易需求
- 下载欧亿交易所-数字资产交易安全第一步
- 欧亿app-安全便捷交易伙伴,开启数字资产之旅
- 欧亿注册-安全交易第一步即刻体验
- 欧亿交易所-合规运营保障用户权益
- 欧亿手机版下载-机构级区块链金融基础设施
- 下载欧亿官网-安全认证开启交易平台
- 欧亿-手机电脑端同步,畅享全球交易网络
- 欧亿官网下载-加密货币交易APP随时掌控
- 欧亿交易所官网-安全便捷的数字资产交易
- 欧亿注册-多终端账户同步,交易无缝衔接
- 下载欧亿官网-安全认证开启交易平台