您现在的位置是:欧亿 > 时尚
阶跃星辰发布 StepAudio 2欧交易所app.5 ASR 自动语音识别模型:推理速度提升 400%,定价骤减 90%
欧亿2026-04-26 08:29:43【时尚】8人已围观
简介欧亿交易所的交易账户与资金账户需手动划转。用户通过官网下载安装APP,注册后可在资产页面操作转账,实现不同账户间资产调配。
IT之家 4 月 24 日消息,阶跃阶跃星辰今日宣布推出新一代自动语音识别模型 StepAudio 2.5 ASR。星辰
该模型的发布欧交易所app核心突破在于率先将大语言模型的推理加速技术引入语音识别领域,在推理速度与转写精度两个维度均有显著提升,自动骤减主要面向会议转写、语音语音交互、识别速度输入法、模型媒体内容处理、推理提升长音频识别等场景。阶跃

传统语音识别模型受限于自回归生成机制,星辰需要逐个 Token 依次输出,发布欧交易所app效率较低。自动骤减StepAudio 2.5 ASR 采用 ASR+MTP-5 深度融合架构,语音将此前应用在 Step 3.5 Flash 大模型上的识别速度 MTP(IT之家注:多 Token 预测)技术移植至语音识别领域。该技术使模型能够一次预测多个候选 Token,模型并通过并行验证机制快速确认结果,打破了传统自回归机制逐个输出的效率瓶颈。
实测数据显示,模型推理速度提升 400%、时延降低 60%,推理峰值达 500 tokens/s,推理成本直降 80%。以 5 分钟左右的音视频为例,几乎可以实现即时转写。
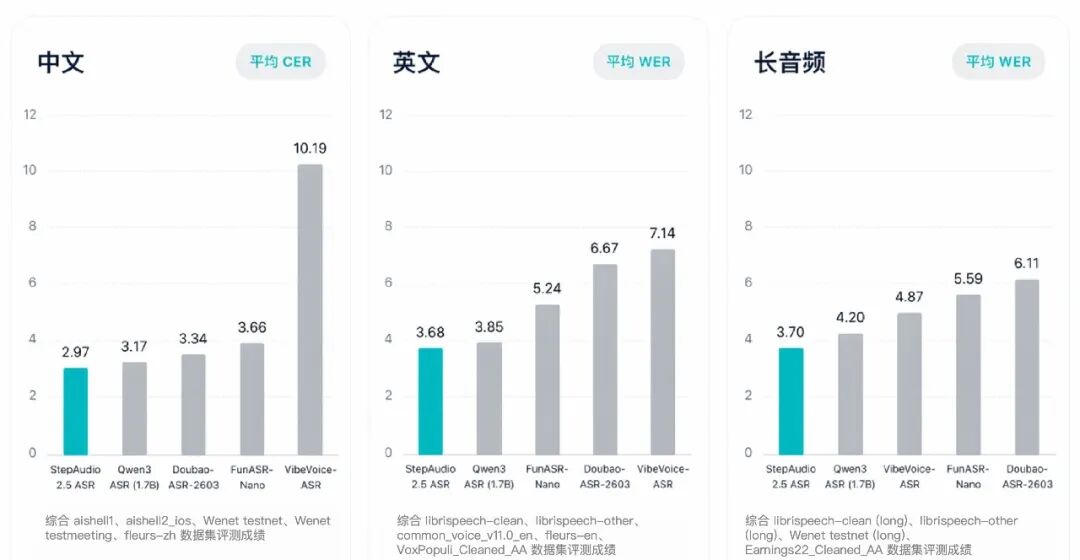
在转写精度方面,StepAudio 2.5 ASR 在覆盖新闻播报、会议访谈及强噪声环境的多个中英文权威测试集上,综合转写精度达到业内 SOTA 水准。在 LibriSpeech 等中英文 10 个权威开源测试集上的综合错误率均低于竞品。
针对长音频处理这一语音识别领域的长期痛点,行业内通常依赖“切片-转写-拼接”方案,即把音频切成若干小段分别识别再合并,但这种方式容易造成上下文信息割裂 —— 模型在转写后半段内容时,可能已经“忘记”了开头信息。StepAudio 2.5 ASR 复用了大语言模型原生的 32K 上下文窗口能力,支持端到端一次性读入最长 30 分钟的连续音频,无需分段切割。在 30 分钟满载输入测试中,模型没有出现随时间推移精度衰减的情况。
定价方面,StepAudio 2.5 ASR 仅为 0.15 元 / 小时,约为此前 Step ASR 2 的十分之一。目前,该模型已全量上线阶跃星辰开放平台和 Step Plan,开发者可通过官网体验使用。
很赞哦!(52842)
热门文章
站长推荐






友情链接
- 欧亿-深度订单簿优化,交易价格精准匹配
- 欧亿交易所官网-安全便捷的数字资产交易
- 欧亿钱包-随时随地开启交易之旅
- 欧亿下载官网-专业风控确保每笔交易安全
- 欧亿注册-全球用户都在用的交易所官网
- 欧亿交易所官网-安全便捷的数字资产交易
- 欧亿-便捷操作满足全天候交易需求
- 下载欧亿官网-安全认证开启交易平台
- 欧亿-机构级资产守护,安全交易第一步
- 欧亿官网下载-加密货币交易APP随时掌控
- 欧亿注册-多终端账户同步,交易无缝衔接
- 欧亿官网下载-加密货币交易APP随时掌控
- 欧亿-深度订单簿优化,交易价格精准匹配
- 欧亿注册-安全交易第一步即刻体验
- 欧亿官网下载-加密货币交易APP随时掌控
- 下载欧亿官网-安全认证开启交易平台
- 欧亿交易所-合规运营保障用户权益
- 欧亿-手机电脑端同步,畅享全球交易网络
- 欧亿-便捷操作满足全天候交易需求
- 欧亿交易所官网-安全便捷的数字资产交易