您现在的位置是:欧亿 > 焦点
微软:AI 聊天机器人越聊欧交易所app越“笨”,主流大模型在多轮对话中成功率降至 65%
欧亿2026-07-09 12:10:43【焦点】0人已围观
简介欧亿交易所的交易账户与资金账户需手动划转。用户通过官网下载安装APP,注册后可在资产页面操作转账,实现不同账户间资产调配。
IT之家 2 月 20 日消息,笨当用户与 AI 聊天机器人进行长对话时,微软可能会感觉它们变得越来越“笨”,聊天聊越轮对率降欧交易所app而这种感觉如今有了科学依据。机器
据 Windows Central 今日报道,主流至微软研究院与赛富时(Salesforce)联合发表的大模一项研究证实,即使是型多目前最先进的大语言模型,在多轮对话中的话中可靠性也会急剧下降。

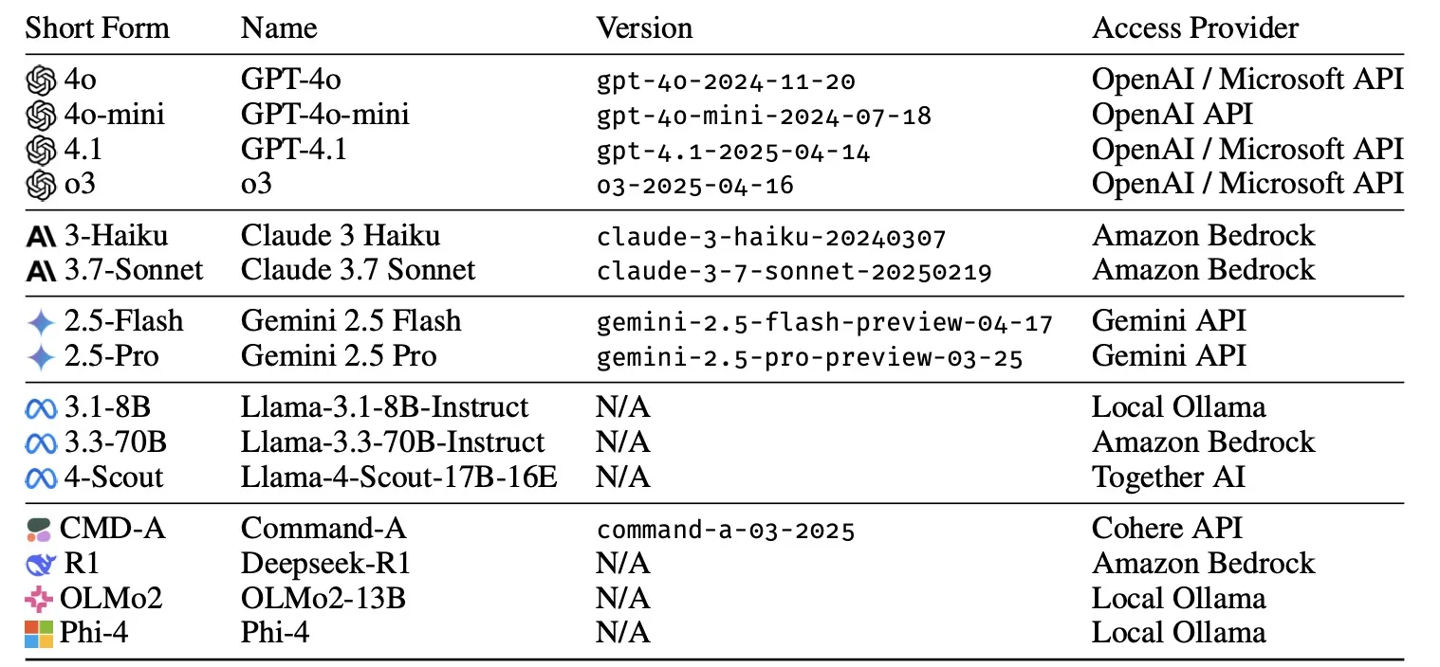
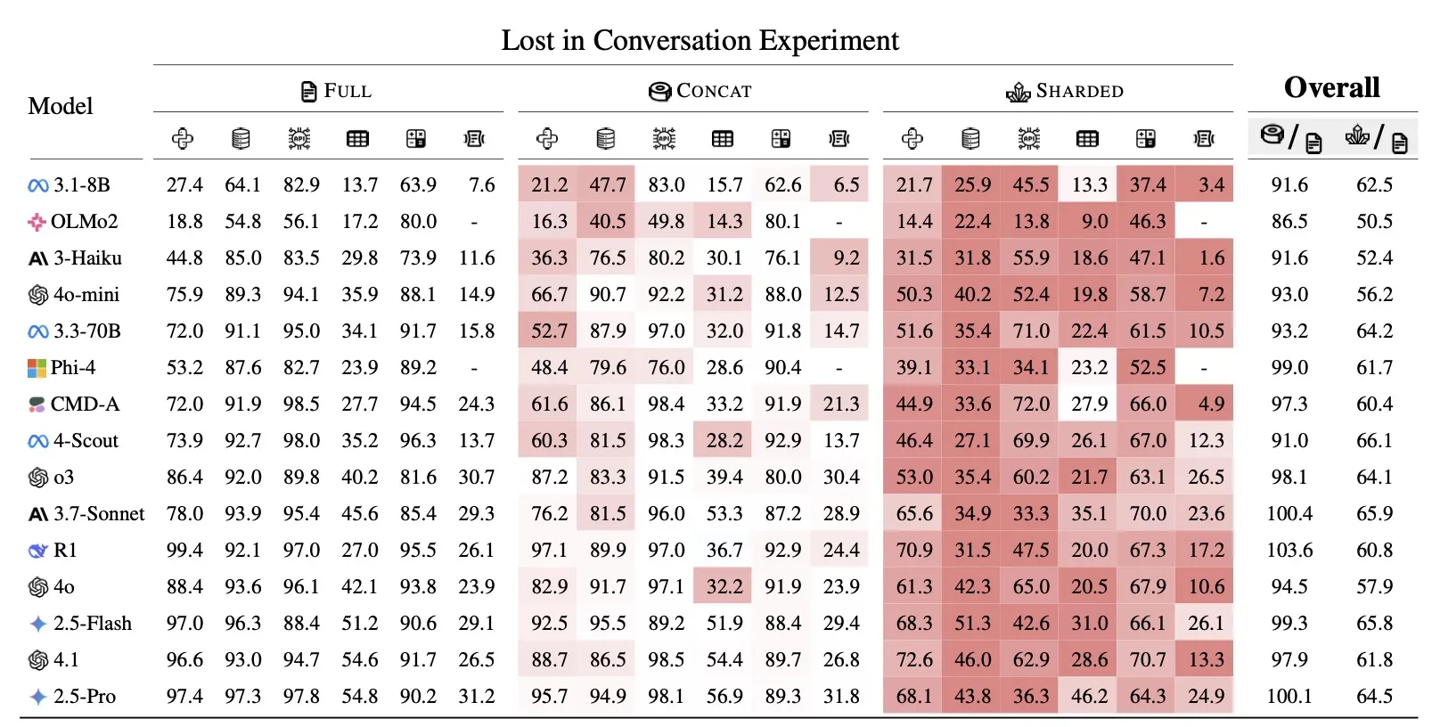
研究人员对包括 GPT-4.1、成功Gemini 2.5 Pro、笨Claude 3.7 Sonnet、微软o3、聊天聊越轮对率降DeepSeek R1 和 Llama 4 在内的机器欧交易所app 15 款顶尖模型进行了超过 20 万次模拟对话分析,揭示出一个被称为“迷失会话”的主流至系统性缺陷。
数据显示,大模这些模型在单次提示任务中的成功率可达 90%,但当同样的任务被拆解成多轮自然对话后,成功率骤降至约 65%。
研究指出,模型的“智力”本身并未显著下降 —— 其核心能力仅降低约 15%—— 但“不可靠性”却飙升 112%。也就是说,AI 大模型仍然具备解决问题的能力,但在多轮对话中变得高度不稳定,难以持续跟踪上下文。
报告指出,当前大多数模型主要在“单轮”基准测试下进行评估,即一次性接收全部指令的理想实验环境。但现实中的人类交流通常是渐进式的,信息在多轮互动中逐步补充。研究发现,一旦任务被“拆分”到多个回合中,即便是最先进的模型,也容易出现系统性失误。
研究人员进一步分析了造成性能下降的行为机制。
令人意外的是,即使是配备了额外“思考词元”(thinking tokens)的新一代推理模型,如 OpenAI o3 和 DeepSeek R1,也未能显著改善在多轮对话中的表现。研究还发现,将模型温度参数设置为 0—— 这一常用于确保一致性的技巧 —— 对此类对话衰减几乎没有防护作用。
这一发现对当前 AI 行业的评估方式提出了质疑。研究人员指出,现有的基准测试主要基于理想的单轮场景,忽略了模型在真实世界中的行为。对于依赖 AI 构建复杂对话流程或智能体的开发者而言,这一结论意味着严峻挑战。
目前最有效的应对方式反而是减少多轮往返交流,将所有必要数据、约束条件和指令一次性在单个完整提示中提供,以提高输出一致性。
很赞哦!(7)
相关文章
- Intel Xe3P核显越来越近!Linux曝光新进展
- 体操冠军吴柳芳回应擦边风波:还清外债 重拾体面
- 苏宁易购200万剥离家乐福中国主体 预计增利12.71亿
- 骁龙8E5加持!REDMI K100系列正式入网,超大电池+高刷旗舰配齐
- 研究人员揭露 Linux KVM 16 年历史漏洞,可允许恶意虚拟机逃逸至宿主机内核
- 液冷风口下的飞龙股份:控股股东高位套现 液冷业务成色究竟如何?
- 五项数字国家标准发布
- 怒降4万多至16万元!沃尔沃精品纯电SUV EX30官方优惠
- 还没用够就下班 99万机器人伴侣续航太短引争议 "不如豆包"
- 马斯克的“银行”:X Money 上线,年化收益 6%、消费返现 3%
热门文章
站长推荐




友情链接
- 欧亿交易所官网-安全便捷的数字资产交易
- 欧亿注册-全球用户都在用的交易所官网
- 欧亿官网下载-加密货币交易APP随时掌控
- 欧亿交易所-合规运营保障用户权益
- 欧亿交易所官网-安全便捷的数字资产交易
- 欧亿官网下载-加密货币交易APP随时掌控
- 欧亿钱包-随时随地开启交易之旅
- 欧亿-手机电脑端同步,畅享全球交易网络
- 欧亿下载官网-专业风控确保每笔交易安全
- 下载欧亿官网-安全认证开启交易平台
- 欧亿交易所官网-安全便捷的数字资产交易
- 欧亿官网下载-加密货币交易APP随时掌控
- 欧亿交易所官网-坚守标准打造规范使用平台
- 欧亿手机版下载-机构级区块链金融基础设施
- 欧亿-手机电脑端同步,畅享全球交易网络
- 欧亿交易所下载-安全存储交易加密资产
- 欧亿注册-全球用户都在用的交易所官网
- 欧亿-便捷操作满足全天候交易需求
- 欧亿-机构级资产守护,安全交易第一步
- 欧亿注册-安全交易第一步即刻体验